深度学习排错指南,主要内容翻译自此PPT,选取了自己认为有用的部分记录。
模型表现差的原因:
- implementation bugs
- hyperparameter choices
- Data/model fit 实验数据质量
- dataset construction: 数据不够,类别不均衡,标签噪声,训练和测试集分布不同
debug困难原因:
- 很难知道是否有bug
- 错误来源很多
- 结果对超参数和数据集组成的小改变很敏感
troubleshooting策略:
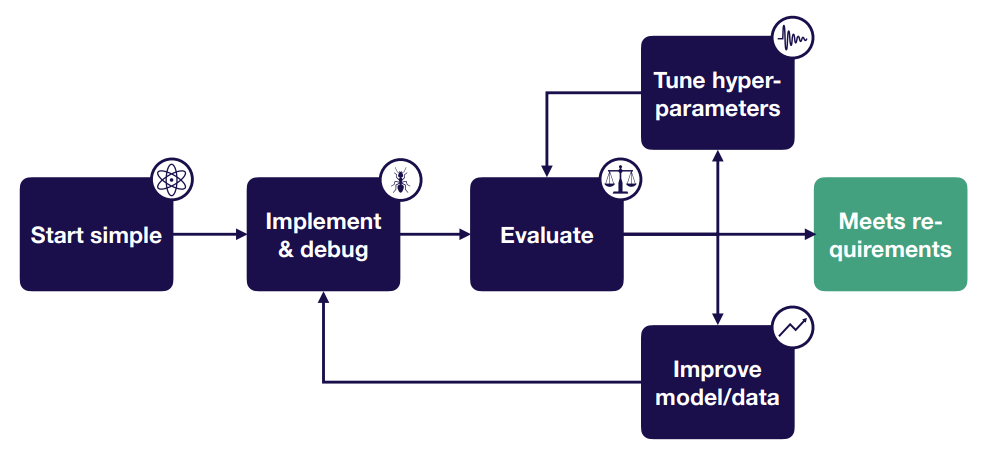
- start simple: 选择最简单的模型和数据
- implement&debug:若能跑起来,试图在一个批次上过拟合 & 重现一个简单、已知的结果(关于过拟合后面详述)
- evaluate:用bias-variance分解来决定下一步
- tune hyper-parameters:用由粗到细随机搜索
- improve model/data:若欠拟合,让模型变大;若过拟合,增加数据和正则项
下面用例子来一步步说明。
假设你已经有:
- 初始测试集
- 一个待提升的评估指标
- 基于human-level performance的目标表现,公开结果,先前的baseline,等等。
比如:
Starting simple
先选一个简单的结构:
| 你的输入数据 | Start | 下一步考虑 |
| :—————: | :———————: | :——————————: |
| 图像 | LeNet | ResNet |
| 文本序列 | 一层隐藏层的LSTM | Attention模型或WaveNet |
| 其它 | 一层隐藏层的FCN | 视问题而定 |特殊情形:多种输入模式,如image caption
用合理的默认值
Optimizer:Adam,学习率3e-4
Activations:ReLu(FC和CNN),tanh(LSTMs)
Initialization:He et al. normal (used for relu) , Glorot normal (used for tanh) (Glorot normal即为Xavier初始化,pytorch里有,或TensorFlow里的 tf.glorot_normal_initializer )

Regulazation:无(可不用)
Data normalization:无
输入归一化:减均值除方差
简化问题:
- 从一个小训练集开始(<10000个实例)
- 用固定的objects数量,类数量,更小的图像尺寸,等等
- 创建一个更简单的人工合成训练集
针对前面那个例子就是:

Implement & debug
==在展开说这部分之前,作者总结了5个最常见的DL bug,可以先逐个排查:==
(1)tensor的shape出错(深表同感),直接报错shape错误就不说了,相对容易排查,需要注意的是能跑起来的错误,一般由广播策略引起。如 x.shape = (None,) , y.shape = (None,1),(x+y).shape = (None,None)
(2)预处理输入出错(原文:Pre-processing inputs incorrectly,有点没理解)。比如,忘记归一化,或预处理过多
(3)损失函数接收的输入出错。比如,对期望收到logits的损失函数输入了softmax结果。
(4)忘记设置train/eval mode。有些策略在train和test时有不同的实现。
(5)数值不稳定,出现Inf/nan。通常源于使用exp、log或div操作。
==在实现模型时的一些建议:==
(1)轻量级实现。少加新代码,实现少于200行(经验)
(2)使用封装好的组件,如Keras。在具体实现上,使用
tf.layers.dense(…)替代tf.nn.relu(tf.matmul(W, x)),使用tf.losses.cross_entropy(…)替代具体实现。(我个人认为在学习阶段更重要的是快速实现想法和按自己的需求改模型,所以Keras和pytorch可能是更好的选择。)(3)以后再学习构造复杂的data生成pipeline。先从可以全部load到内存的数据开始。
让模型跑起来
常见错误:
shape不匹配。
常见原因:(1)sum,average,softmax操作在错误的维度(2)卷积层后忘记展平tensor(3)忘记去掉多余的“1“维度,如 (1,1,4) (4)存在磁盘上的数据类型与load时不符,比如存了个float64的numpy array,load的是float32。
解决:开debugger,逐步进行模型创建和测试
数据类型错误。
OOM。
常见原因:(1)tensor太大。一般是因为(evaluation时)batch size过大,或庞大的全连接层。(2)数据太多。load太多数据到内存,而不是用输入队列;或为创建数据集分配过大的buffer。(3)冗余的操作。可能在一个Session里创建了太多模型,或重复调用某个操作。
(4)有人占了你的卡(其实这条最实用)
解决:逐项删掉占用内存密集的操作。
其它。
常见原因: 忘记初始化变量;Forgot to turn off bias when using batch norm(这条不清楚什么意思?)
解决:使用标准debugg工具包,如stack overflow和交互式debugger
不同的框架有不同的debugger,pytorch的ipdb比较简单,代码如下:
1
import ipdb; ipdb.set_trace()
作者给出的两种使用方法:


不是很明确,用到的时候再搜一下用法。
在一个batch上过拟合
常见错误:
error上升
常见原因:(1)loss function或梯度的符号反了 (2)学习率太高 (3)softmax时对应的维度出错
error爆炸
常见原因:(1)数值问题,检查exp、log和div操作 (2)学习率太高
error震荡
常见原因:(1)数据或标签出错,如zeroed,错误shuffled,预处理出错 (2)学习率太高
error平稳
常见原因:(1)学习率太低 (2)梯度没有传递给整个模型(梯度消失) (3)太多正则化 (4)loss function的输入出错(比如,输入了softmax而不是logits) (5)数据或标签出错
与已知结果比较
作用由高到低:
在你用的数据集上有官方模型实现
可按行输出中间结果,看是否有相同输出。
在benchmark上有官方模型实现
可按行输出中间结果,看是否有相同输出。
非官方模型实现
paper结果(只能对比预期指标)
Evaluate
一般认为:Test error = irreducible error(无法消除的误差项) + bias + variance + val overfitting
但前提是训练、验证、测试数据服从相同分布,如果出现下面这种情况:

称为分布偏差(distribution shift),由于验证集一般是从训练集中选择的,因此与训练集具有同分布。此时验证集的结果并没有泛化到测试集的能力。
此时:Test error = irreducible error + bias + variance + ==distribution shift== + val overfitting
Improve model/data
优先考虑bias-variance tradeoff:解决欠拟合、解决过拟合、解决distribution shift、平衡数据集
- 解决欠拟合(降低偏差)
- 让模型变得“更大”,横向增加hidden size,纵向增加layers
- 减少正则项
- 误差分析
- 选择不同的模型结构(如从LeNet转到ResNet)
- 调整超参
- 增加features
- 解决过拟合(降低方差)
- 增加训练数据(可能的话)
- 增加normalization(如batch norm,layer norm)
- 数据增强(data augmentation)
- 增加正则项(dropout,L2,权重衰减)
- 解决distribution shift(优先级从高到低)
- 分析test-val set的误差,收集更多训练数据来补偿
- 分析test-val set的误差,合成更多训练数据来补偿
- 将领域适应技术应用于训练集和测试集分布(Apply domain adaptation techniques to training & test distributions)。什么是domain adaptation?就是在源分布上训练完后,只用无标注数据或有限的标注数据将模型泛化到目标分布。可以理解为迁移学习。
- 平衡数据集
- 解决欠拟合(降低偏差)
Tune hyperparameters
经验法则:
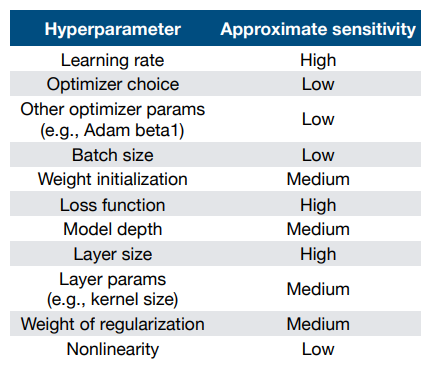
人工调参
首先要理解算法,理解每个超参的作用。比如,更高的learning rate意味着学得更快,但会降低学习的稳定性。其次就是不断训练和验证模型,用经验去“猜”更好的超参数,或手动选择参数范围。
grid search
自动枚举各种参数组合。但效率很低。
随机搜索
随机设置参数组合,选择表现好的一个区域,再次随机搜索,缩小范围。一般可以选到很好的超参数,实际中最常用。
贝叶斯超参数优化
结论
- DL debugger很难,因为错误来源非常广
- 为了得到bug-free的模型,我们应当把模型构建过程当作一个迭代过程
learn more
- Andrew Ng’s book Machine Learning Yearning (http://www.mlyearning.org/)
- The following Twitter thread: https://twitter.com/karpathy/status/1013244313327681536
- This blog post: https://pcc.cs.byu.edu/2017/10/02/practical-advice-for-building-deep-neuralnetworks/

