有监督参数估计是指已知分类器结构或函数形式,从训练样本中估计参数。
本文主要介绍贝叶斯决策(详见贝叶斯决策的过程)条件概率密度的有监督参数估计过程。方法有最大似然估计和贝叶斯参数估计法。
最大似然估计
假设参数为确定值,根据似然度最大进行最优估计。
给定数据
表示不同类别的样本。假设每类样本独立同分布(i.i.d. 万年不变的假设),用$D_i$来估计$θ_i$,即对每个类求一个判别函数,用该类的样本来估计判别函数的参数。

注意区分特征空间和参数空间。参数估计的任务是得到$p(x|w_i)$的形式,是在参数空间进行的。不妨设特征空间为d维,参数空间p维。
为了估计参数,需要如下几个步骤:
求似然(Likelihood) 注意,上面这个式子针对的已经是具体的类别$w_i$了,不要问$w$参数去哪了。另外,这里的n代表样本数目,要和前面的类别数目c区分开。这个式子很好理解,即出现我们当前观测到的样本概率,求使它最大化的参数即可。
最大化似然
这个梯度是在p维参数空间求解,即求解梯度。可求解析解或梯度下降。(常用Log-Likelihood,易求解)
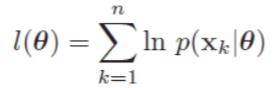
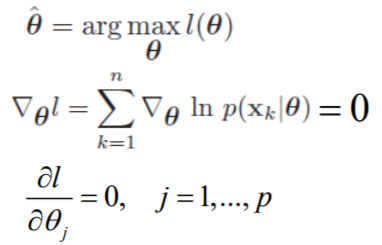
当先验$P(\theta)$都相等时等同于最大后验概率(MAP)决策。
高斯密度最大似然估计
以贝叶斯决策过程里给出的高斯密度假设为例,对它进行最大似然参数估计。首先假设$\sigma$已知,对$\mu$进行估计。
单点情况:
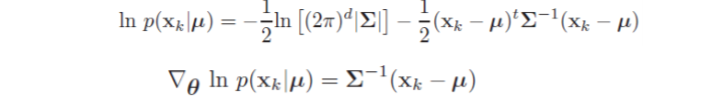
对于所有样本:
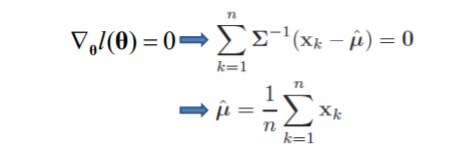
估计值即为观测样本均值。
再来看$\mu$和$\sigma$都未知的情况。设数据服从一维高斯分布,$\theta_1=\mu$,$\theta_2=\sigma^2$:
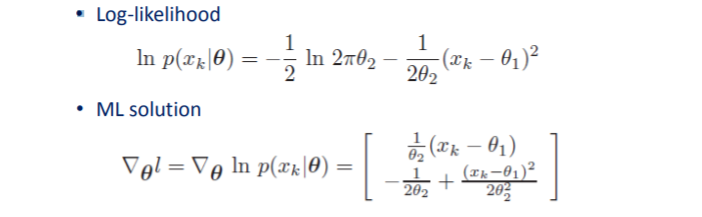
令梯度等于0可求得:
多维情况,$\theta_2=\Sigma$:
估计结果类似无偏估计。
贝叶斯参数估计
参数被视为随机变量,估计其后验分布
我们先来简化一下贝叶斯决策的条件概率密度形式。考虑训练样本对分类决策的影响,后验概率可写作:
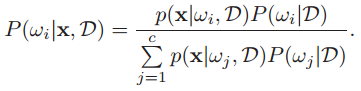
首先由于先验概率一般可以事先得到,因此通常不考虑样本对它的影响。其次,我们使用的是有监督学习,训练样本自然都会分到各自所属的类中。基于这两点可简化公式,得到公式一:
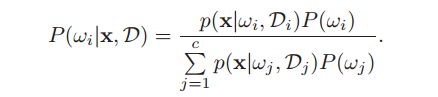
由此我们需处理的其实是c个独立的问题,那么条件概率密度可简写成c个$P(x|D)$,分别对它们进行估计。
下面引出参数分布估计的过程。假定参数形式已知,即已知$p(x|θ)$,为求$p(x|D)$:
由于测试样本x(观测样本)和训练样本D的选取是独立的,因此可写成公式二:
样本独立性是《模式分类第二版》里对这步变换做出的解释。对这一部分说一下我的理解。按书里说的x与D相互独立,那p(x|D)其实直接就可以简写成p(x),且$p(\theta)$也假定已知(后面会说),直接
不就能求了,为什么非要对条件概率密度引入D呢?
其实这样做的目的就是为了强行引入$p(\theta|D)$。别忘了$p(x|D)$实际上是$p(x|\omega,D)$,来自公式一。回顾一下公式一引入D的原因,是尽可能地利用已有的全部信息来估计后验概率$p(\omega|x)$,对$p(x|D)$也是这样。即便训练样本对观测值x没有影响,但我们希望再引入一个受样本影响的reproducing density $p(\theta|D)$,让它影响类条件概率的分布。其实相当于重新构造了一个先验,并希望$p(\theta|D)$在$\theta$的真实值附近有显著的尖峰(sharp)。通常可以用这个sharp逼近的$\hat\theta$来替代真实值,有$p(x|D) ≈ p(x|\hat\theta)$。如果估计值的置信度不高(用高斯分布来说即方差较大,sharp不明显。后面会说),也可以按$p(\theta|D)$对$\theta$进行采样,带入$p(x|\theta)$求平均:
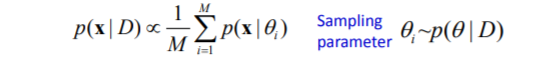
总结一下,公式一和公式二是贝叶斯决策和参数估计的两个核心部分。尤其是公式二,我们希望把$p(x|D)$和$p(θ|D)$联系起来,那么已有的训练样本就能通过$p(θ|D)$对$p(x|D)$施加影响。至此我们已经把有监督学习问题(原始分类问题)转换成了一个无监督的概率密度预测问题(估计$p(θ|D)$)。
高斯密度贝叶斯估计
对高斯密度假设进行贝叶斯参数估计。
考虑一维情况。$p(x|\mu)\sim N(μ,σ^2)$,假设$σ^2$已知,为了预测$p(μ|D)$,写成:
由于$p(D|\mu)=\prod_{k=1}^np(x_k|μ)$,则
$\alpha$是原式分母,作为常数项。
假设$p(μ)\sim N(μ_0,σ_0^2)$,$\mu_0$和$\sigma_0^2$已知。可以把$\mu_0$看作对$\mu$的先验估计,$\sigma_0^2$看作估计的不确定程度。做正态分布假设只是为了简化后面的数学运算。这一步的重点在于在参数估计过程中我们是已知参数先验概率密度$p(\mu)$的。
公式展开:
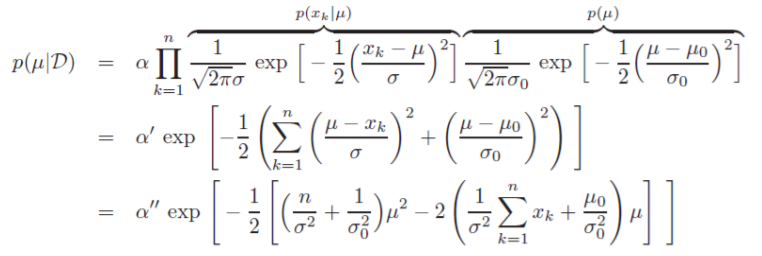
与μ无关的因子都被归入$\alpha$中。可见$p(μ|D)$仍符合高斯分布,对照标准形式可得
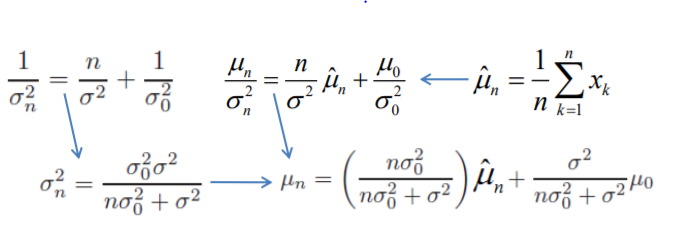
到目前为止,已经把先验知识$p(\mu)$和训练样本信息$\hat\mu_n$结合在一起,估计出了后验概率$p(\mu|D)$。把结果直观地写在一起:
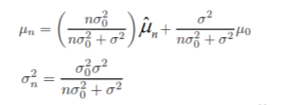
在这个结果中,$\mu_n$表示在观测到n个样本后,对参数$\mu$真实值的最好估计,$\sigma_n^2$则代表这个估计的不确定性(前面对先验假设也是这么解释的,理解一下高斯分布对参数估计的理论意义)。$\sigma_n^2$随着n的增大而减小,即增加训练样本后,对$\mu$真实估计的置信度将逐渐提高,呈现一个sharp。这样的过程称为贝叶斯学习过程。
将$p(\mu|D)$代入
得出$p(x|D)\sim{N(μ_n,σ^2+σ_n^2)}$。因此,根据已知的$p(x|μ)\sim{N(μ,σ^2)}$,只要用$μ_n$替换μ,$σ^2+σ_n^2$替换$σ^2$即可完成参数估计。
我们观察到,当n趋于无穷时,贝叶斯参数估计与最大似然效果相同。(当然在实际问题当中样本往往是有限的,这里只是形式化地理解)
总结一下贝叶斯估计的一般过程:

最大似然和贝叶斯估计的比较
在上面的例子中,用贝叶斯参数估计与ML分别对条件概率密度$p(x|\omega)$进行估计,得到的虽然都是高斯分布形式,但这个过程中做的假设是完全不同的。ML直接假定$p(x|\omega)$符合高斯分布,根据训练样本选取确定的参数$\hat\mu$和$\hat\sigma^2$。而贝叶斯估计方法是通过假设已知$p(x|θ)$和$p(\mu)$符合高斯分布,推出$p(\mu|D)$符合高斯分布, 进而根据公式二推出$p(x|D)$符合高斯分布。这个分布的sharp作为估计的均值,随样本数增加而改变,且确信度逐渐升高。
高斯分布的例子相对来说有点抽象,《模式分类》里还给了一个简单的例子,比较好理解,尤其是这幅图:
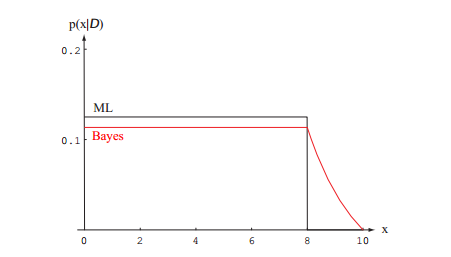
非常有助于理解。贝叶斯估计在样本最大值之外还有一个拖尾,这就是考虑了先验$p(\theta)$的结果,告诉我们在x=10附近,条件概率密度仍可能不为0。(详见书中例1 递归的贝叶斯学习)
总的来说,最大似然估计根据训练样本明确估计出最优参数值,而贝叶斯估计目标是求出参数的分布,类似于“参数为0.5的概率为0.8”。虽然在估计时模糊的结果(即近似正确)往往更有用,但贝叶斯估计计算复杂度较高,可理解性较差,因此最大似然估计应用更广泛。

